
With the rise of large language models (LLMs), techniques like Retrieval-Augmented Generation (RAG) have become essential for maintaining factuality, improving accuracy, and enabling real-time knowledge access. But the quality of a RAG system depends heavily on the quality of the underlying search engine.
At Tavily, we’ve built a real-time AI search engine that integrates seamlessly into LLM pipelines, helping reduce hallucinations, deliver accurate answers, and power applications that demand up-to-date, grounded information. Recently, we benchmarked our retrieval system on OpenAI’s SimpleQA benchmark, achieving state-of-the-art (SOTA) results with 93.3% accuracy. This blog outlines our evaluation methodology, presents the results, compares static and dynamic benchmarks, and explains why we believe dynamic benchmarking is crucial for real-world systems.
Why RAG Systems Depend on Great Search
Whether you call it RAG (Retrieval-Augmented Generation), SAG (Search-Augmented Generation), or custom LLM agents, the effectiveness of these architectures depends on two things: accurate document retrieval and response grounding.
Tavily’s real-time search acts as a high-precision layer for LLMs, retrieving fresh, relevant web content. This minimizes reliance on stale internal knowledge, reduces model hallucinations, and improves answer correctness — all while dramatically cutting latency.
Evaluating Tavily on OpenAI’s SimpleQA
SimpleQA is a benchmark released by OpenAI, featuring 4,326 short-form factual questions, each paired with a ground-truth answer. It was designed to measure:
- Retrieval quality: How relevant are the documents retrieved?
- Answer accuracy: Can the LLM generate a correct answer using only the retrieved documents?
This benchmark is ideal for stress-testing the factual precision of LLM + retrieval pipelines in a controlled, reproducible environment.
Evaluation Setup
We followed OpenAI’s published methodology: each SimpleQA question was sent to Tavily’s real-time search API, which returned high-quality web documents. Based on these documents, GPT-4.1 answered the question using only the information contained within them, with no prior knowledge allowed. The response was then evaluated using OpenAI’s correctness prompt.
Check out this link to our GitHub repository of SimpleQA evaluation and a results comparison across different LLMs and search providers.
Benchmark Results
Tavily achieved 93.3% accuracy on OpenAI’s SimpleQA benchmark without using complex reasoning or deep research techniques — a state-of-the-art result in factual correctness and grounding.
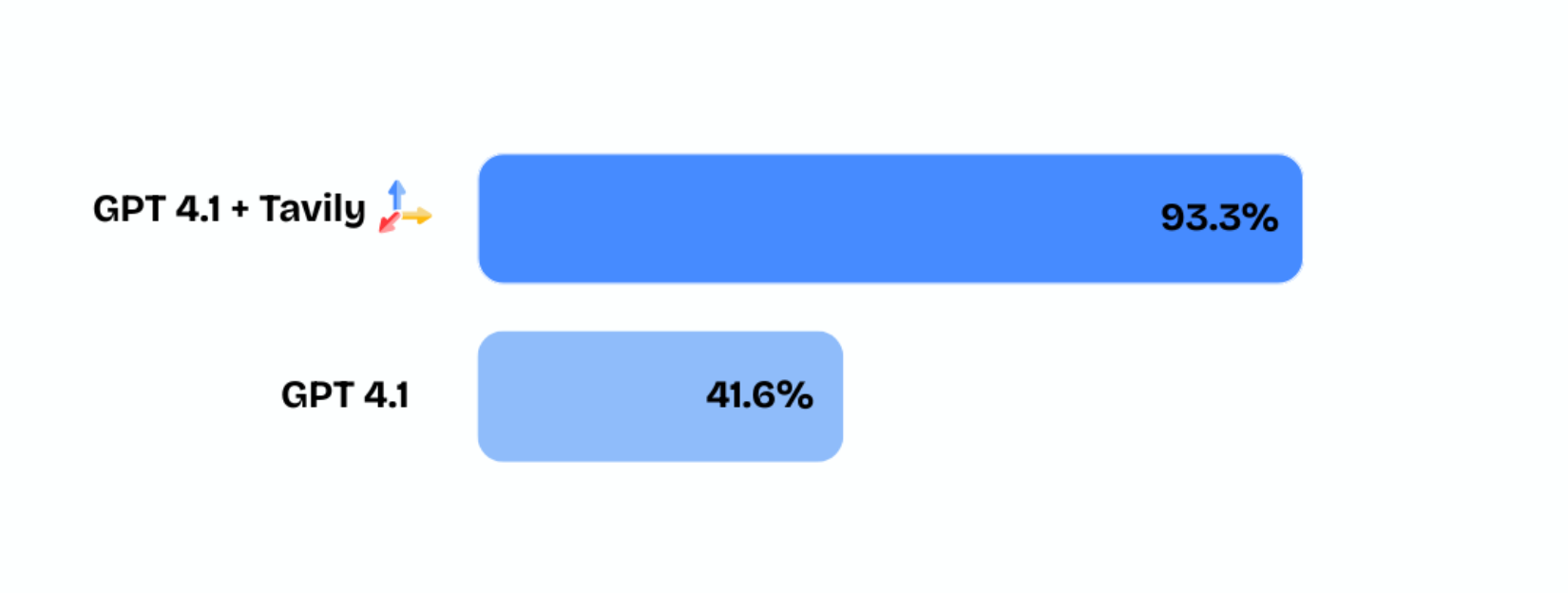
Our system powered GPT-4.1 to deliver accurate answers without using any pre-trained knowledge, relying exclusively on real-time, direct, and non-iterative search results from the web. The results demonstrate that high-quality retrieval alone can massively boost LLM output fidelity.
- Accuracy: 93.33%
- Performance boost over baseline: ~51.7%
- Knowledge source: 100% grounded in retrieved documents
With ~92% less latency per question, and without utilizing reasoning or deep research, Tavily's score trails the most advanced Perplexity Deep Research model by only 0.6% (93.9% vs. 93.3%).
This means Tavily is a fast and lightweight solution for any product that requires high factual precision, especially in production environments with tight latency constraints.
Beyond Static Benchmarks
While SimpleQA helps assess factual grounding in controlled conditions, it doesn’t reflect the complexity of real-world scenarios. In production, questions can be ambiguous, time-sensitive, and span constantly evolving information. Static benchmarks alone don’t cut it.
To address this, we developed and open-sourced the Dynamic Eval Dataset Generator — a tool for building realistic, web-based RAG benchmarks aligned with live content and continuous evaluation workflows.
What’s Next
Following our collaboration with Quotient AI, we were able to confirm what we expected: dynamic evaluation is more challenging — and more representative of real-world performance. We found:
- Dynamic questions are significantly harder, exposing meaningful performance gaps.
- Reference-free document relevance provides stronger signals than answer-only scoring.
These insights mark the beginning of a new approach to measuring retrieval quality in fast-changing environments.
👉 In Part 2 of this blog series, we’ll share:
- How we built a dynamic evaluation agent for web search
- Why reference-free document scoring may outperform answer-only metrics
- What developers need to know about testing retrieval in the web
- Performance comparison across different search providers
Stay tuned!