TL;DR
Hybrid RAG integrates the reliability of static vector databases with the timeliness of real-time web search. Tavily’s Search API delivers LLM-ready context with citations and controllable freshness windows. The hybrid client merges local and web results, persisting valuable web insights back into the knowledge base so that it evolves continuously, staying accurate and up to date.
Introduction
Retrieval-Augmented Generation (RAG) has become a cornerstone for building reliable AI applications. By retrieving external documents and feeding them into a model, RAG improves accuracy, reduces hallucinations, and enables domain-specific grounding.
However, two recurring challenges emerge in practice:
- Local knowledge bases drift out of date unless constantly re-ingested.
- Web integrations are noisy, often returning raw HTML that is unsuitable for direct use with AI systems.
What is needed is the stability of curated vector stores combined with the freshness of the web, without constant manual updates.
Tavily Hybrid RAG offers this structured solution. It unifies retrieval from internal knowledge bases with real-time, citation-ready web search, while giving developers fine-grained control over recency, domains, and search depth. The result is a system that balances trusted in-house knowledge with live external data, making it production-ready for scenarios that demand both accuracy and timeliness.
Static vs. Dynamic Knowledge in RAG
When designing a RAG workflow, teams inevitably face the trade-off between static and dynamic knowledge:
- Static knowledge (vector databases, curated document stores): reliable and domain-specific, but at risk of becoming stale.
- Dynamic web data: fresh and comprehensive, essential for fast-changing contexts such as regulations, market news, or product updates, but often noisy and inconsistent.
Neither approach is sufficient on its own. Static-only systems miss new developments, while dynamic-only systems risk hallucinations. Hybrid RAG bridges this gap.
Why Tavily is Purpose-Built for Hybrid RAG
Unlike traditional search engines that return unstructured HTML, Tavily is designed for AI pipelines. Its Search API delivers clean, modular chunks optimized for LLM context windows.
Key differentiators include:
- Customizable chunks: Pre-sized segments designed to fit LLM windows.
- Scoring metadata: Relevance scores for each snippet, enabling intelligent filtering.
- Built-in context filters: Fine-tune freshness, search depth, and domain restrictions.
- Citations by default: Every snippet is auditable and traceable.
- Intelligent filtering: Noise and redundancy are minimized to preserve tokens and improve precision.
This provides developers with AI-ready data, seamlessly merging with internal knowledge sources for contextually rich, reliable outputs.
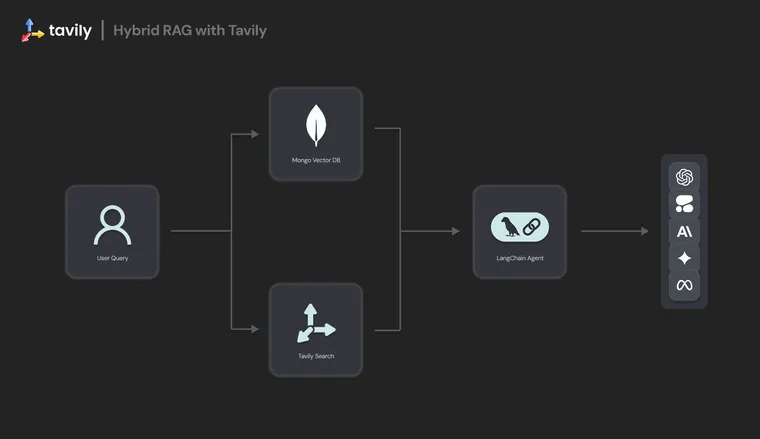
Hybrid RAG in Tavily
The TavilyHybridClient provides a unified retrieval layer that merges:
- Local retrieval from vector databases (e.g., MongoDB).
- Web retrieval from Tavily’s real-time Search API.
The client handles me rging, reranking, and tagging of results by origin—ensuring downstream LLMs can balance trusted in-house content with live external intelligence transparently.
Deep Dive: Setup and Workflow
Install the required packages:
pip install tavily-python pymongo cohere
Set your API Keys:
export TAVILY_API_KEY="tvly-your-api-key"
export CO_API_KEY="your-cohere-api-key"
Create a MongoDB vector search index:
{
"fields": [
{
"path": "embeddings",
"type": "vector",
"similarity": "cosine",
"dimensions": 1024
}
]
}
Initialization Parameters and Hybrid Client
The TavilyHybridClient class is the core component that makes hybrid retrieval simple to implement.
from tavily import TavilyHybridClient
client = TavilyHybridClient(
api_key="your_tavily_api_key",
db_provider="mongodb", # Local DB backend
collection="knowledge_base", # Collection name
embeddings_field="vector", # Field for embeddings
content_field="text" # Field for document content
)- api_key: Tavily Search API key
- db_provider: backend type (currently supports MongoDB)
- collection: the collection to use for retrieval
- embeddings_field: where embeddings are stored in your DB
- content_field: where raw document text is stored
Hybrid Search Mechanics
The retrieval process is handled by the search() method:
results = client.search(
query="Latest developments in AI regulation",
max_results=8,
max_local=4,
max_foreign=4,
save_foreign=True
)
Key parameters:
- max_results: total results returned
- max_local / max_foreign: control mix of local and web results
- save_foreign: persist web results into the local DB for future use
The system merges local and web results, reranks them for relevance, and tags each with its origin. This transparency helps with prompt construction, allowing developers to decide how much weight to give local versus web context.
How Hybrid Search Works
The TavilyHybridClient performs three key operations:
- Local Vector Search: Queries the MongoDB collection using vector similarity
- Web Search: Searches the web via Tavily's API with the same query
- Intelligent Merging: Combines and reranks results using Cohere's reranker
Embeddings and Reranking
By default, Tavily integrates Cohere embeddings and reranking. Custom embedding or ranking functions can be supplied to optimize retrieval for domain-specific applications (e.g., finance, healthcare, legal), through a custom embedding_function or ranking_function.
Real-World Example: Financial Intelligence
A financial research workflow can combine internal investment reports with live market news:
from pymongo import MongoClient
from tavily import TavilyHybridClient
from datetime import datetime
import openai
# Connect to MongoDB (use your actual connection string)
mongo_client = MongoClient("mongodb+srv://username:password@cluster.mongodb.net/")
collection = mongo_client["knowledge_base"]["documents"]
# Initialize Tavily Hybrid RAG
hybrid_client = TavilyHybridClient(
api_key="tvly-your-api-key", # Use actual API key
db_provider="mongodb",
collection=collection,
index="vector_search_index",
embeddings_field="embeddings",
content_field="content"
)
# Perform hybrid search
results = hybrid_client.search(
query="Tesla Q4 2024 earnings analysis",
max_results=10,
max_local=6,
max_foreign=4,
save_foreign=True,
include_domains=['reuters.com', 'bloomberg.com', 'sec.gov'],
time_range="week"
)
def generate_financial_analysis(query):
client = openai.OpenAI(api_key="your-openai-api-key")
results = hybrid_client.search(
query=query,
max_results=8,
max_local=5,
max_foreign=3,
save_foreign=True
)
context_parts = []
for result in results:
source_label = "INTERNAL RESEARCH" if result['origin'] == 'local' else "MARKET INTELLIGENCE"
context_parts.append(f"[{source_label}] {result['content']}")
context = "\n\n".join(context_parts)
# Updated API call
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": "You are a financial analyst. Synthesize internal research with current market data."
},
{
"role": "user",
"content": f"Context:\n{context}\n\nQuery: {query}\n\nProvide analysis:"
}
]
)
return response.choices[0].message.content
This enables seamless synthesis of internal Q3 analysis with breaking Q4 updates, producing insights that are both grounded and current.
Use Cases: Where Hybrid RAG Excels
Hybrid RAG is especially powerful where both accuracy and recency are essential:
- Markets and finance: Combine historical earnings with real-time news.
- Product and documentation: Pair manuals with the latest release notes or security advisories.
- Research and innovation: Bridge long-term literature reviews with daily breakthroughs.
- Customer support: Blend internal policies with real-time service updates.
Operational Benefits
- Lower latency over time: Cached web results reduce repeated network calls.
- Dynamic freshness: Responses stay current without sacrificing reliability.
- Scalability without retraining: Retrieval improves system accuracy without costly model retraining.
Conclusion
Tavily Hybrid RAG enables the development of AI systems that are both accurate and current. By merging stable internal knowledge with real-time, citation-backed web search, teams can avoid the trade-off between outdated local data and noisy external sources.
For enterprises deploying AI agents into production, Hybrid RAG reduces maintenance overhead, ensures transparency, and delivers timely insights. It represents a scalable, turnkey solution for building production-grade RAG systems that reflect the world as it is today—not just at the last ingestion point.
👉 Explore the Tavily SDK documentation to get started with Hybrid RAG today.