
Introduction
Every data science enthusiast knows that a vital first step to building a successful model or algorithm is having a reliable evaluation set to aspire to. In the rapidly evolving landscape of Retrieval-Augmented Generation (RAG) and AI-driven search systems, the importance of high-quality eval datasets is crucial.
In this article, we introduce an agentic workflow designed to generate subject-specific dynamic evaluation datasets, enabling precise validation of web search augmented agents' performance.
Known RAG evaluation datasets, such as HotPotQA, CRAG, and MultiHop-RAG, have been pivotal in benchmarking and fine-tuning models. However, these datasets primarily focus on evaluating performance with static, pre-defined document sets. As a result, they fall short when it comes to evaluating web-based RAG systems, where data is dynamic, contextual, and ever-changing.
This gap presents a significant challenge: how do we effectively test and refine RAG systems designed for real-world web search scenarios? Enter the Real-Time Dataset Generator for RAG Evals — an agentic tool leveraging Tavily’s Search Layer and LangGraph framework to create diverse, relevant, and dynamic datasets tailored specifically for web based RAG agents.
What is the Real-Time Dataset Generator?
If you’ve ever built an AI agent, you already know that evaluating it is just as challenging as creating it. When it comes to research agents or tailoring an agent for a specific subject, the process can become even more daunting. Why? Because it’s often a tedious, manual process — one that involves crafting domain-specific queries, curating relevant data, and ensuring the results align with the agent’s objectives. This approach is not only time-consuming but also prone to inconsistencies.
At its core, the Real-Time Dataset Generator is an agent designed to create datasets for evaluating other agents, automating the tedious processes of query generation, web data collection, and filtering. This enables developers and researchers to focus on building smarter, more capable agents.
The Generator offers a powerful solution for evaluating how effectively LLM based agents handle fact-based, up-to-date questions in time-sensitive domains such as news-focused agents delivering real-time updates, sports agents providing accurate game statistics, financial agents analyzing market trends, and more. By generating dynamic datasets aligned with current events, this tool ensures agents can be rigorously tested and refined for precise and relevant responses.
How it works?
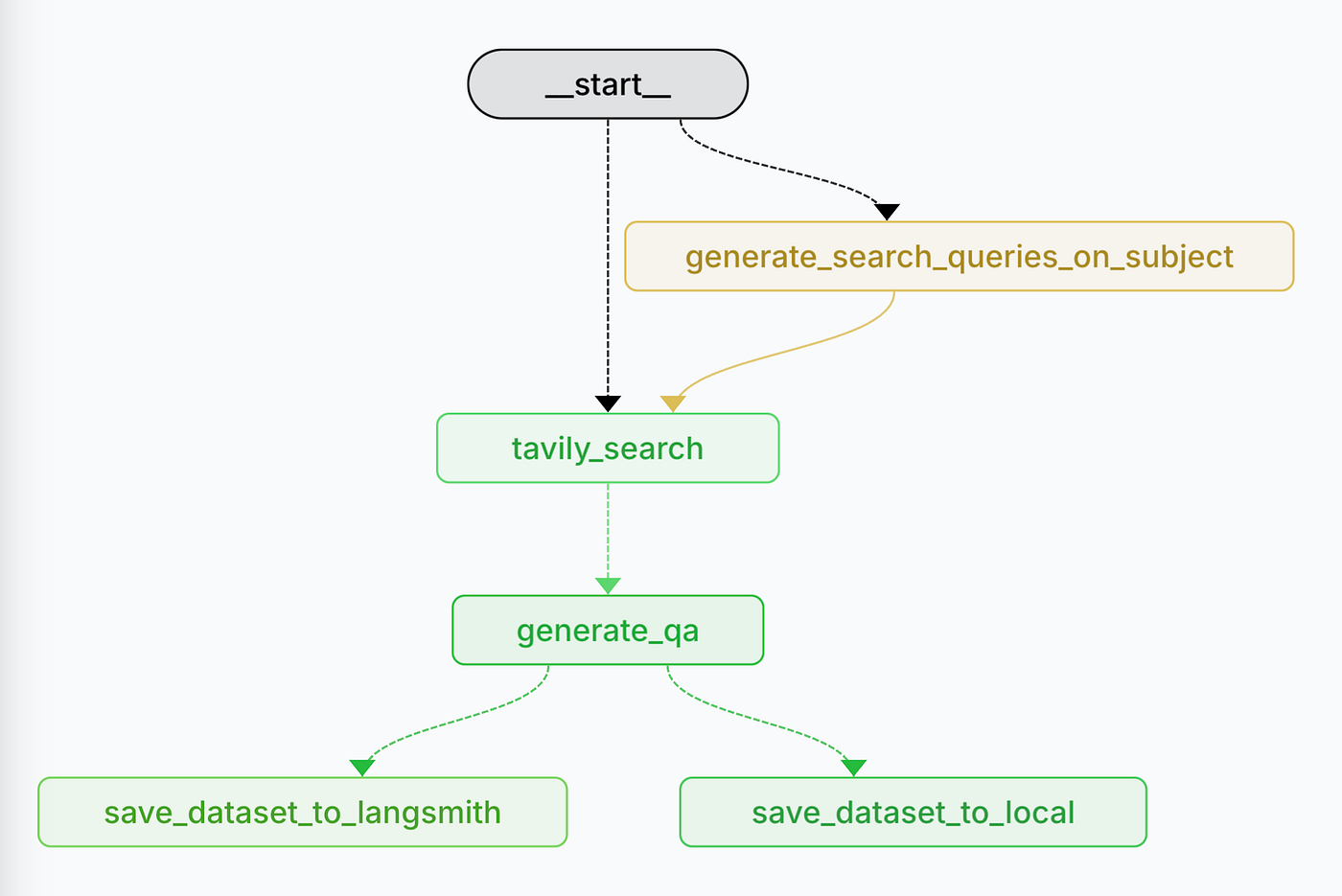
Step 1: Input
The workflow begins with user-provided inputs:
input = {num_qa: "number of questions and answers",
QA_subject: "subject of the Q&A",
save_to_langsmith: "save locally or to Langsmith"}Step 2: Domain Specific Search Query Generation
If a subject is provided (e.g., “NBA Basketball”), the system generates a set of search queries using this prompt:
QA_QUERIES_SYSTEM_PROMPT = """
**Objective:**
Produce {num_queries} clear, effective, and varied queries to gather the most relevant and recent information about the input subject.
**Guidelines:**
1. Ensure clarity, specificity, and relevance to the subject.
2. Prioritize fresh and comprehensive results.
"""This ensures queries are tailored to gather high-quality, recent, and subject-specific information.
Step 3: Web Search with Tavily
This step guarantees that the dataset reflects current and relevant information, particularly for web search RAG evaluation, where up-to-date data is crucial.This is the heart of the RAG Dataset Generator, transforming queries into actionable, high-quality data that forms the foundation of the evaluation set.
query_with_date = f"{query} {datetime.now().strftime('%m-%Y')}"
tavily_response = await self.tavily_client.search(
query=query_with_date,
topic="news", # Focuses search on recent news articles.
days=3, # Searches content from the past 3 days.
max_results=5 # Limits results to the top 5 most relevant sources.
)Key Parameters of Tavily Search:
topic="news":
Narrows the search to news-related content, targeting fresh and reliable sources.days=3:
Searches for content published within the last three days, keeping the dataset relevant for real-world evaluation scenarios.max_results=5:
Retrieves up to five highly relevant results per query, avoiding information overload while maintaining quality.
Step 4: Q&A Pair Generation
For each website returned by Tavily, the system generates question-answer pair using a map-reduce paradigm to ensure efficient processing across multiple sources. This step is implemented using LangGraph’s Send API.
def map_qa(state):
# Map Function
return [Send("generate_qa", {"page_content": result.get('content', '')})
for url,result in state.search_results.items()]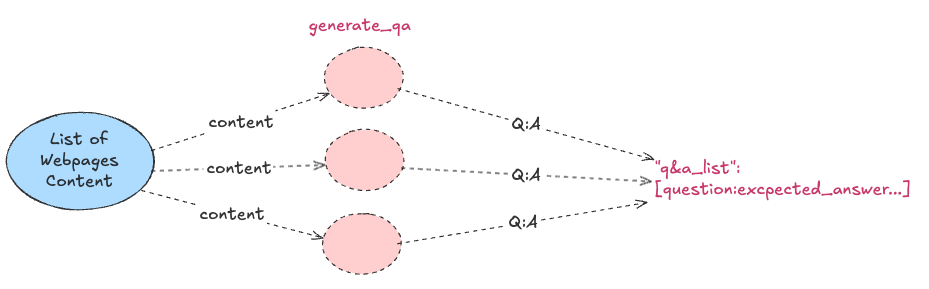
# nodes/generate_qa.py
from web_search_benchmark_generator.prompts import QA_GENERATION_SYSTEM_PROMPT,QA_GENERATION_USER_PROMPT
from langchain_core.messages import HumanMessage, SystemMessage
from pydantic import BaseModel,Field
from typing import List, Dict
from web_search_benchmark_generator.state import QAState
class QA(BaseModel):
question: str = Field(
...,
description="A question generated from the content."
)
answer: str = Field(
...,
description="The corresponding answer to the question."
)
class QAList(BaseModel):
qa_list: List[QA] = Field(
...,
description="A list of QA pairs, each containing a question and its corresponding answer."
)
class QAGenerator:
def __init__(self,cfg,utils):
self.model = cfg.LLM
self.cfg = cfg
self.default_system_prompt = QA_GENERATION_SYSTEM_PROMPT
self.default_user_prompt = QA_GENERATION_USER_PROMPT
self.utils = utils
async def run(self, state: QAState):
"""
Generate 10 question-and-answer pairs based on the given page content.
Args:
state (QAState): The state containing the page content.
Returns:
List[Dict[str, str]]: A list of dictionaries containing question-answer pairs.
"""
msgs = "🤔 Running QA Generator"
if self.cfg.DEBUG:
print(msgs)
page_content = state['page_content']
# Create system and user messages for the model
system_message = SystemMessage(content=self.default_system_prompt)
user_message = HumanMessage(
content=self.default_user_prompt.format(page_content=page_content)
)
messages = [system_message, user_message]
try:
response = await self.model.with_structured_output(QAList).ainvoke(messages)
return {"q_and_as":response.qa_list}
except Exception as e:
# Handle and log errors
msgs += f"Error in QA Generator: {e}"
if self.cfg.DEBUG:
print(msgs)
raise ValueError(f"Failed to generate QA pairs: {e}")Step 5: Save the Evaluation Set
Finally, the generated dataset is saved either locally or to Langsmith, based on the input configuration.
# Create the dataset
dataset = self.client.create_dataset(
dataset_name=dataset_name,
description=self.description,
)
# Prepare inputs and outputs for bulk creation
inputs = [{"question": qa.question} for qa in qa_list]
outputs = [{"expected_answer": qa.answer} for qa in qa_list]
# Save the examples
self.client.create_examples(
inputs=inputs,
outputs=outputs,
dataset_id=dataset.id,
)
return {"output_message": f"Dataset '{dataset_name}' saved in langsmith, You can access the dataset via the URL {dataset.url}."}Output
The result is a well-structured, subject-specific evaluation dataset, ready for use in advanced evaluation methods like LLM-as-a-Judge.
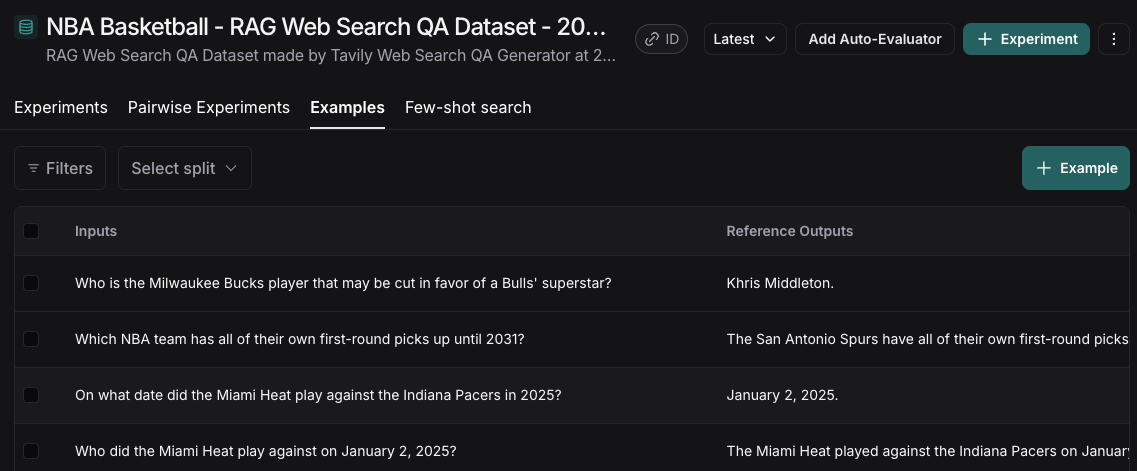
Evaluation of the Dataset Using LLM-as-a-Judge
Once the dataset is generated, its quality and relevance can be assessed using the LLM-as-a-Judge approach. This involves leveraging large language models to evaluate the accuracy, coherence, and completeness of the generated question-answer pairs. The LLM acts as an unbiased evaluator, scoring the answers based on alignment with expected outcomes or factual correctness. This method provides a scalable, automated way to validate datasets, ensuring they meet high standards for RAG system evaluation.
An LLM-as-a-judge prompt example:
llm_judge_prompt = """
You are an unbiased evaluator tasked with assessing whether the generated answer aligns with the expected answer based on the provided question.
Evaluate the generated answer's accuracy, coherence, and completeness compared to the expected answer.
Provide a score from 1 to 10 for each criterion, followed by a brief explanation.
Question: {question}
Expected Answer: {expected_answer}
Generated Answer: {generated_answer}
Evaluation:
- Accuracy: [Score: 1-10] - [Does the generated answer align with the expected answer?]
- Coherence: [Score: 1-10] - [Is the generated answer clearly written and logically presented?]
- Completeness: [Score: 1-10] - [Does the generated answer fully address the question as intended by the expected answer?]
- Overall Feedback: [Your observations and suggestions for improvement]
"""Getting Started with the Dataset Generator
Getting started with the Dataset Generator is easy and straightforward. For the full repository and detailed instructions, click HERE.