In AI research, accuracy is critical. Outdated data? Not useful. Models generating false information? A serious issue. And if you’ve ever tried gathering insights on companies with minimal online presence—or on similarly named entities—you know that many tools often fall short. That’s where Tavily’s Company Researcher comes in. This tool integrates Tavily Search and Extract, in a workflow powered by LangGraph, to deliver precise, reliable insights. Instead of just surface-level data, it generates comprehensive, current reports with in-depth detail.
Tavily’s Intelligent Search Layer
Tavily’s mission is to provide an intelligent search layer that connects large language models (LLMs) to the web, giving agents access to real-time, contextually relevant data. Tavily supports flexible search capabilities, enabling AI agents to fine-tune search strategies, retrieve raw content for analysis, or pull summaries for quick insights. Unlike static models bound to training data, Tavily’s Search and Extract endpoints combine semantic, contextual, and keyword search to deliver timely, relevant insights for data-driven decision-making.
How the Company Researcher Works
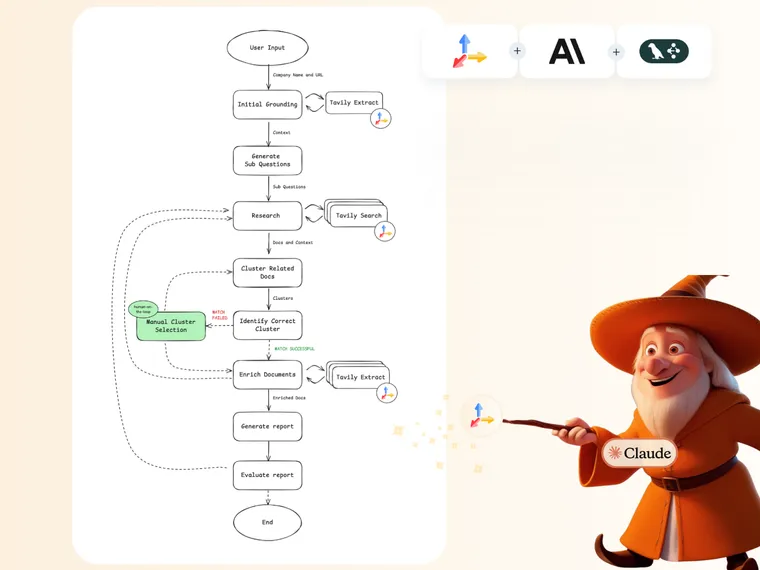
The Company Researcher automates a multi-stage workflow for real-time company analysis, integrating search and extraction with agentic behavior to generate high-quality results. Its modular and dynamic architecture allows for efficient gathering of both general context and targeted data. The use of feedback loops, combined with optional human-on-the-loop validation, ensures precise and reliable outputs. Here’s how it works:
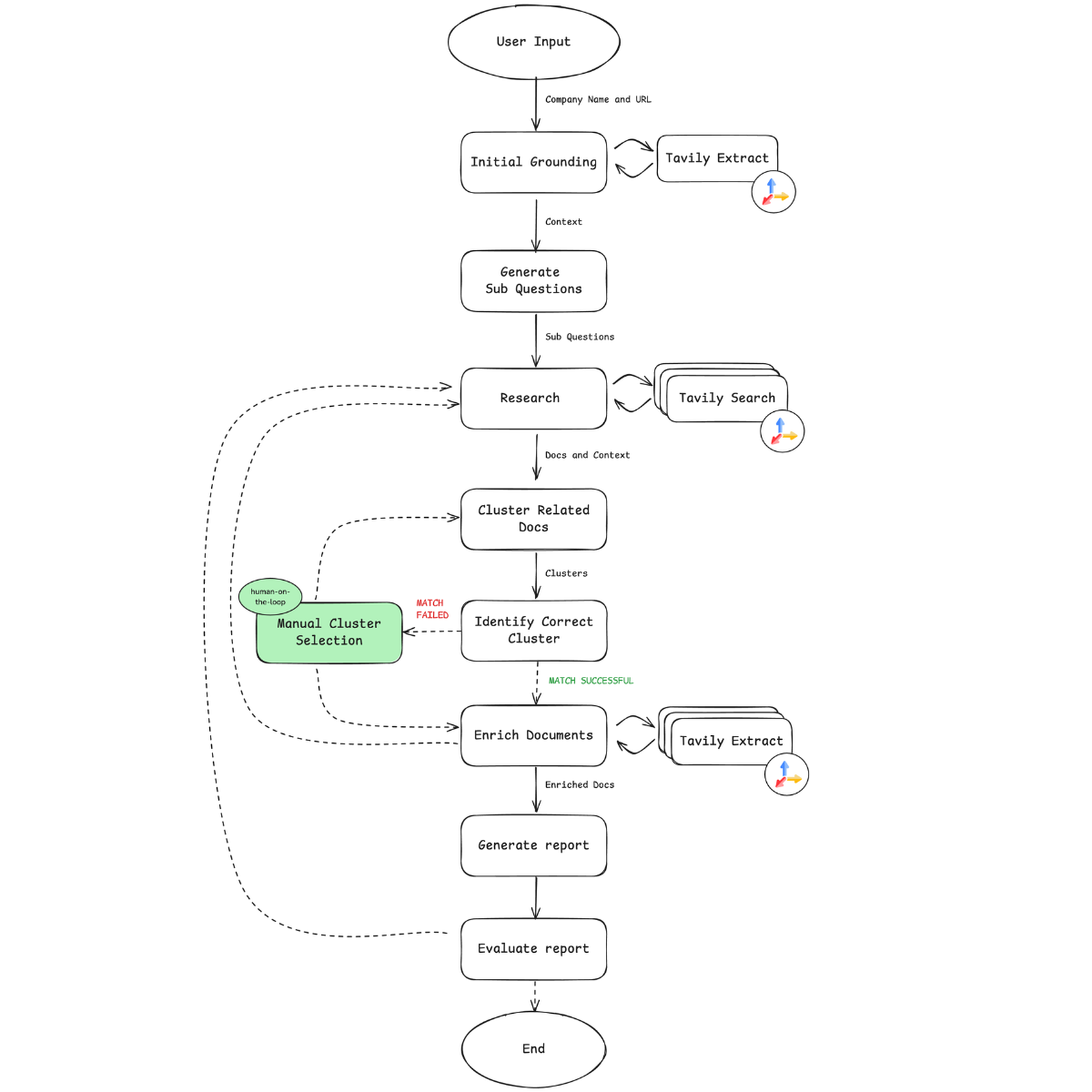
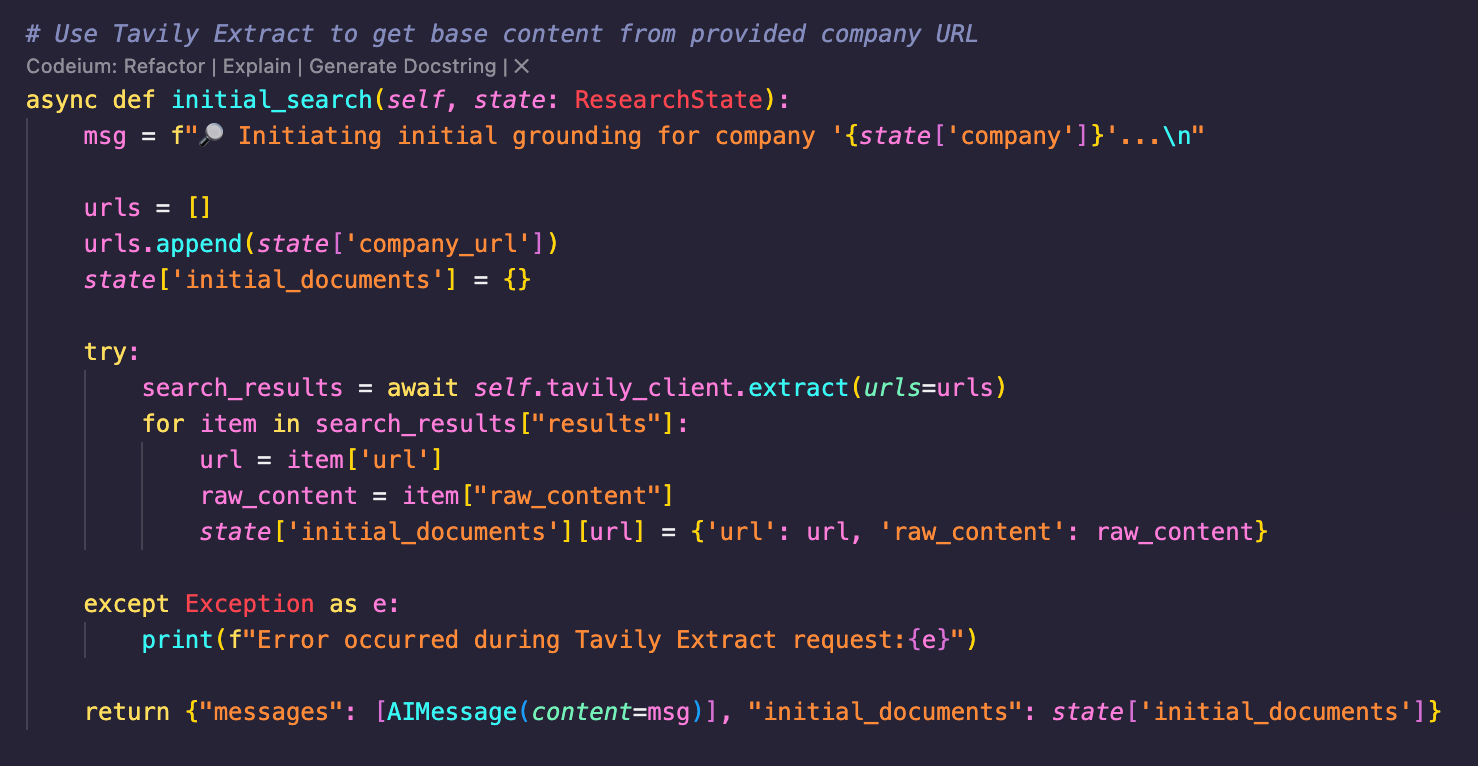
- Initial Grounding with Tavily Extract: Each session begins with a user-provided company name and URL. Tavily Extract retrieves content from that site, creating a “ground truth” that anchors the search to follow. By grounding in verified data, each step operates within set accuracy boundaries, reducing hallucinations and inconsistencies.
- Sub-Question Generation and Tavily Search: Dynamically generates specific sub-questions to guide Tavily’s search, focusing the search on high-value, relevant data instead of conducting a broad, unfocused search.
- AI-Driven Clustering: Retrieved documents are grouped by company, using the ground truth to verify accuracy, especially for similarly named entities. This clustering keeps only relevant sources in focus.
- Human-on-the-Loop for Cluster Validation: If clustering doesn’t yield a definitive match, meaning that the correct cluster wasn't automatically identified, optional human validation can make manual adjustments, ensuring data quality.
- Document Curation and Enrichment with Tavily Extract: Once a trusted cluster is identified, Tavily Extract pulls detailed data from these verified links, adding substantial depth to the research. This step enhances the precision and comprehensiveness of the final output.
- Report Generation and Evaluation: An LLM synthesizes the data into a structured report. If gaps are detected, new questions are generated to gather additional data, improving the report without restarting.
- Multi-Format Output: The final report is available in PDF or Markdown format, making it easy to share and integrate.
Here is how I define the workflow IRL:
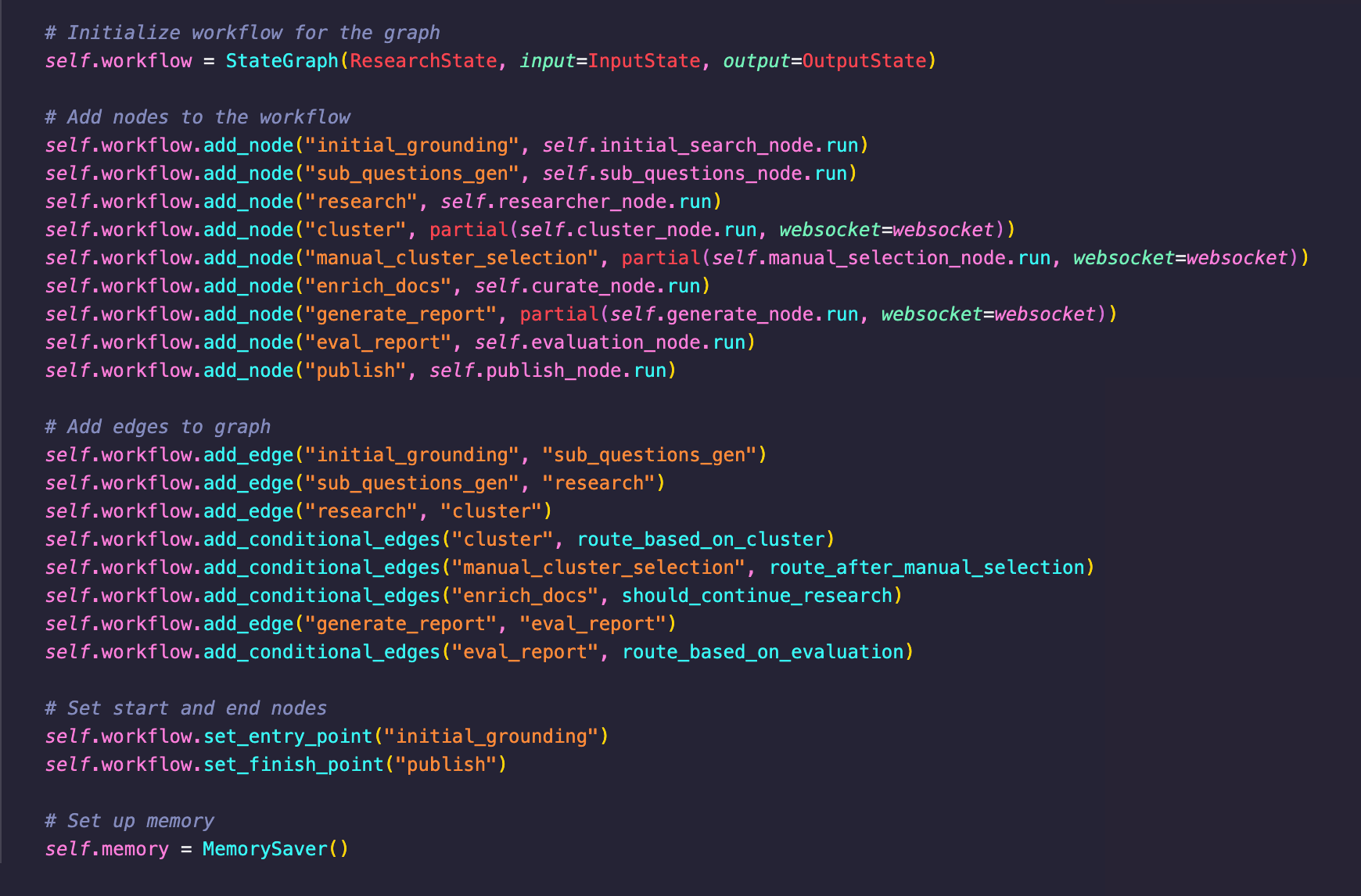
Key Technical Features
Grounding: The Foundation of Accuracy
Grounding is core to Tavily’s Company Researcher workflow. It starts with establishing a reliable “ground truth” by using Tavily Extract on a verified company URL. This keeps the system aligned to the correct entity, especially in cases where similarly named companies exist. Creating a foundation to work from minimizes unrelated or erroneous information, improving output accuracy. Feedback loops that refer to the “ground truth” coupled with human-on-the-loop validation further reinforce this foundation, ensuring outputs are consistently relevant and curated for quality.
Tavily Search and Extract: Better Together for Precision
Tavily Extract is geared to pull raw information from specified sources. Allowing the agent to dig deep on the most important sources without the pressure of having to explore every possible lead. Tavily Search on the other hand, looks at the breadth of the web to identify the most relevant sources for your goal. By going broad it will ensure the scope of your research needs are covered. Tavily’s Company Researcher shows how you can utilize the strengths of each and have both tools work with one another to generate the results you want. In the end, only the most relevant pages are analyzed, providing accurate, contextually rich information, minimizing long context windows, and resulting in precise, actionable reports.
Dynamic Graph-Like Structure: Flexibility Meets Predictability
The Company Researcher uses a dynamic, graph-based structure that balances clear paths with flexibility. Traditional deterministic workflows work well for set steps but struggle in unpredictable real-world contexts. Fully dynamic workflows, like ReAct, handle unpredictability better but can lack structure and deterministic accuracy. The Company Researcher’s hybrid approach, implemented with LangGraph, maintains a clear path while adapting to real-world, real-time challenges, allowing for flexibility when data inputs vary.
Structured Output: Consistency in Data
Structured prompting ensures output consistency. While early LLMs could provide accurate information, their formatting was often inconsistent. I addressed this by embedding specific formatting into prompts, so each data cluster follows a set structure, making results easy to retrieve, reliable, and consistently organized.
Here is an example of how it is used to define the clusters:
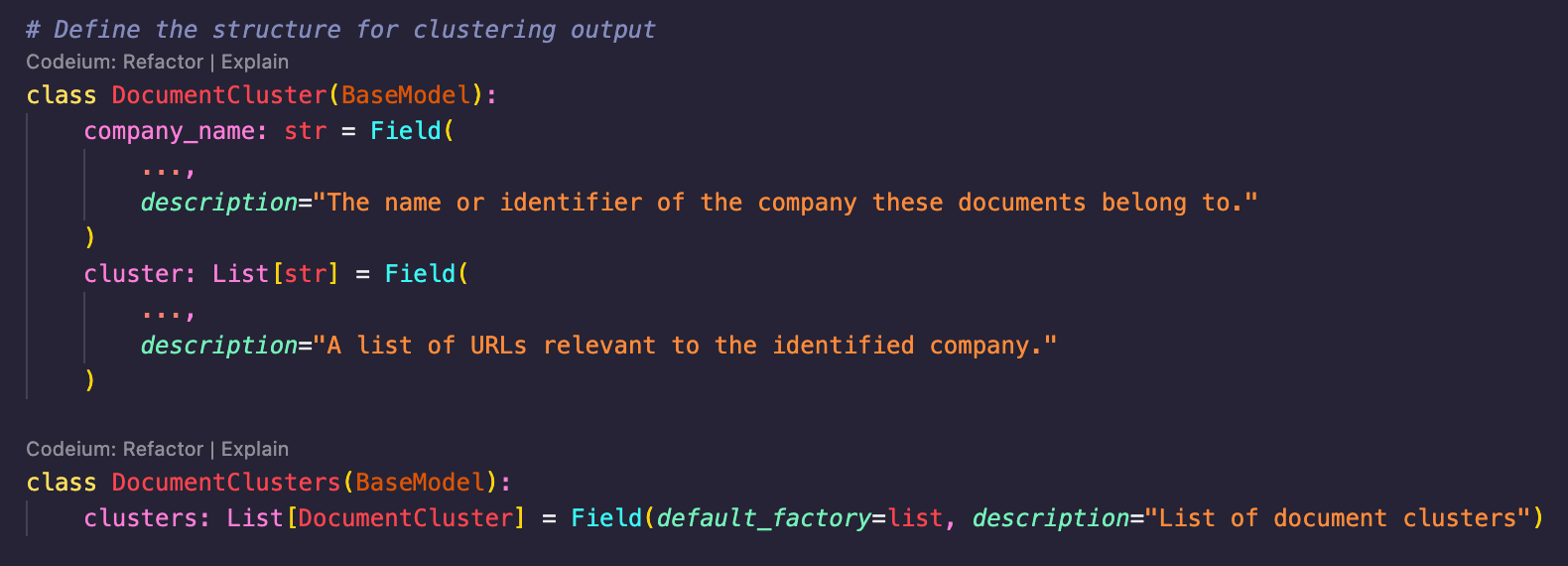
And it is even simpler to call:

Then, you can access each type of output because it is assigned to the cluster through the defined structure:

And the Best Part: It’s Adaptable!
Tavily’s Company Researcher can be easily customized to fit a range of research needs. By making simple adjustments, you can expand its use beyond company research to tackle various data-intensive tasks, ensuring consistent and reliable results.
- Modify Prompts: Consider tailoring the prompts used for question generation or report synthesis to better align with your specific research goals.
- Extend Workflow Nodes: Think about adding, removing, or altering workflow nodes to target specific types of analysis or areas of interest.
- Customize Output Formats: Don’t hesitate to adjust output formats, such as using custom CSS for PDF styling, to align with your organization’s standards.
Getting Started with Company Researcher:
In this section, we will walk you through the steps to download and start using Company Researcher.
Prerequisites
- Python 3.11 or later: Python Installation Guide
- Tavily API Key - Sign Up
- Anthropic API Key - Sign Up
Installation
- Clone the Repository:
git clone https://github.com/danielleyahalom/company-researcher.git
cd company-researcher- Create a Virtual Environment:
To avoid dependency conflicts, it's recommended to create and activate a virtual environment using venv:
python -m venv venv
source venv/bin/activate # macOS/Linux
venv\Scripts\activate # Windows- Set Up API Keys:
Configure your Anthropic and Tavily API keys as environment variables or place them in a .env file:
export TAVILY_API_KEY={Your Tavily API Key here}
export ANTHROPIC_API_KEY={Your Anthropic API Key here}- Install Dependencies:
pip install -r requirements.txt- Run the Application:
python app.py- Open the App in Your Browser:
http://localhost:5000